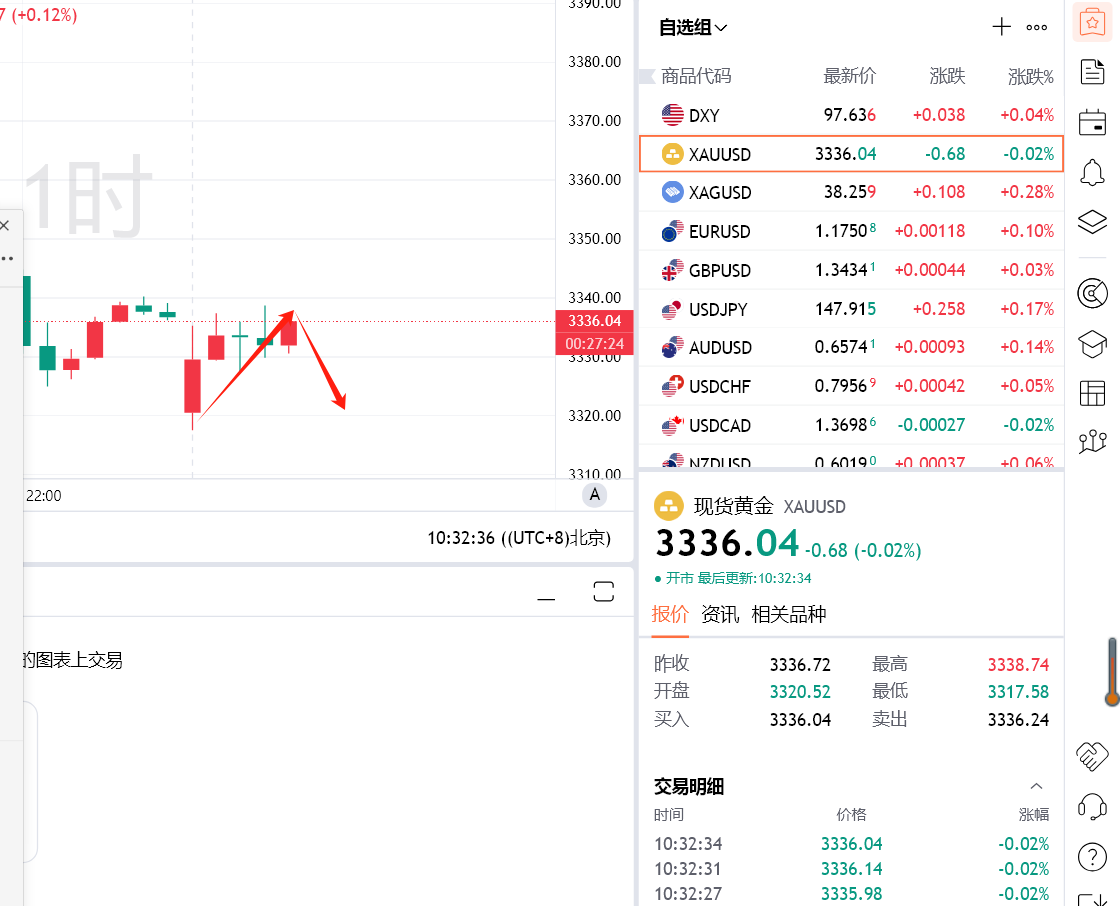
йӮў_жҳҹпјҡ3600зӮ№йңҮиҚЎжӢүй”ҜпјҢ科жҠҖдё»зәҝејәеҠҝзӘҒеӣҙ
зҡ®зҗғиғ–иғ–пјҡзңјеүҚжҒҗжғ§дёҺиҙӘе©ӘдәӨз»ҮпјҢж“ҚдҪңдёҠжңүдёҖзӮ№йҡҫеәҰ
第е…ӯж„ҹи§үпјҡеҰӮдҪ•и§ЈиҜ»еӨ§зӣҳзҡ„е°Ҹйҳіжҳҹе‘ўпјҹ
иӮЎеҝғпјҡеҚҒеҖҚиӮЎеј•йўҶи¶ӢеҠҝпјҢеҗҺз»ӯеҰӮдҪ•еҸӮдёҺпјҹ
зҹӯжңҹжҲҗдәӨдёҚжҳ“ејӮеёёеҸҳеҢ– 7жңҲ28ж—ҘеёӮеңәжңҖејәзғӯзӮ№пјҒ
3600зӮ№йңҮиҚЎеҺҹеӣ дёҺзғӯзӮ№жҖқиҖғ ж–°дё»еҚҮжөӘпјҢи¶ӢеҠҝжҳҺжң—пјҒ
2025е№ҙдё–з•Ңдәәе·ҘжҷәиғҪеӨ§дјҡдёҠпјҢвҖңAIиөӢиғҪж–°еһӢе·ҘдёҡеҢ–вҖқжҲҗдёәжңҖе…·зҺ°е®һеј еҠӣзҡ„зғӯиҜҚд№ӢдёҖгҖӮд»Һз”ҹжҲҗејҸAIеҲ°е…·иә«жҷәиғҪжңәеҷЁдәәпјҢд»Һе·Ҙдёҡж“ҚдҪңзі»з»ҹеҲ°иЎҢдёҡеӨ§жЁЎеһӢпјҢAIжӯЈиҜ•еӣҫдёҖжӯҘжӯҘжү“йҖҡеә•еұӮи®ҫеӨҮгҖҒдёӯеұӮзі»з»ҹдёҺйЎ¶еұӮеҶізӯ–зҡ„зәөж·ұй“ҫжқЎгҖӮ
гҖҖгҖҖжҚ®йәҰиӮҜй”Ўи°ғз ”жҳҫзӨәпјҢд»Ҡе№ҙ1жңҲиҜ„йҖүеҮәзҡ„е…Ёзҗғ17家вҖңзҒҜеЎ”е·ҘеҺӮвҖқдёӯпјҢAIеё®еҠ©е…¶еңЁеҲ¶йҖ жҲҗжң¬гҖҒз”ҹдә§е‘Ёжңҹж—¶й—ҙе’Ңзјәйҷ·зҺҮзӯүж–№йқўж”№е–„50%д»ҘдёҠгҖӮ然иҖҢпјҢиҝҷдәӣе·ҘеҺӮдёӯжҺ’еҗҚеүҚдә”зҡ„з”ЁдҫӢжңү77%еә”з”ЁеҲ°еҲӨеҲ«ејҸAIпјҢд»…жңү9%еә”з”ЁеҲ°з”ҹжҲҗејҸAIгҖӮ
гҖҖгҖҖе’ЁиҜўе…¬еҸёGartnerйў„жөӢпјҢеҲ°2029е№ҙпјҢдёӯеӣҪ60%зҡ„дјҒдёҡе°ҶжҠҠAIиһҚе…Ҙдё»иҰҒдә§е“ҒдёҺжңҚеҠЎпјҢ并дҫқжүҳе…¶жҲҗдёәж ёеҝғиҗҘ收й©ұеҠЁеҠӣгҖӮдҪҶд»ҺвҖңе®һйӘҢе®ӨвҖқиө°иҝӣвҖңиҪҰй—ҙең°жқҝвҖқпјҢAIиҰҒз©ҝйҖҸе·ҘдёҡдҪ“зі»зҡ„еӨҡж ·жҖ§гҖҒеӨҚжқӮжҖ§е’Ңй«ҳеҸҜйқ жҖ§иҰҒжұӮпјҢиҮіе°‘иҝҳжңүдёүеә§вҖңзЎ¬еұұвҖқйңҖиҰҒзҝ»и¶ҠпјҡдёҖжҳҜй«ҳиҙЁйҮҸж•°жҚ®ж”¶йӣҶеӣ°йҡҫпјҢдәҢжҳҜжЁЎеһӢе№»и§үйҡҫд»Ҙе®№еҝҚпјҢдёүжҳҜеңәжҷҜйҖӮй…Қйҡҫд»Ҙ规模еӨҚеҲ¶гҖӮ
гҖҖгҖҖиҝҷдёҚд»…жҳҜдёҖеңәз®—жі•иғҪеҠӣзҡ„з«һиөӣпјҢжӣҙжҳҜдёҖеңәе·ҘдёҡзҗҶи§ЈеҠӣдёҺзі»з»ҹе·ҘзЁӢеҠӣзҡ„й•ҝи·‘гҖӮ
гҖҖгҖҖй«ҳиҙЁйҮҸж•°жҚ®жҳҜеүҚжҸҗжқЎд»¶
гҖҖгҖҖеңЁйҖҡз”ЁеӨ§жЁЎеһӢиҝҲеҗ‘е·ҘдёҡеңәжҷҜзҡ„иҝҮзЁӢдёӯпјҢй«ҳиҙЁйҮҸж•°жҚ®дёҚжҳҜеҠ еҲҶйЎ№пјҢиҖҢжҳҜеҶіе®ҡжЁЎеһӢиғҪеҗҰиҗҪең°зҡ„еүҚжҸҗжқЎд»¶гҖӮ
гҖҖгҖҖдёӯеӣҪз”өеӯҗдҝЎжҒҜдә§дёҡеҸ‘еұ•з ”究йҷўдҝЎжҒҜеҢ–дёҺиҪҜ件дә§дёҡз ”з©¶жүҖеҸ‘еёғзҡ„з ”з©¶жҠҘе‘ҠжҢҮеҮәпјҢжө·йҮҸй«ҳиҙЁйҮҸж•°жҚ®жҳҜеӨ§жЁЎеһӢжіӣеҢ–ж¶ҢзҺ°иғҪеҠӣзҡ„еҹәзЎҖгҖӮд»ҺиЎҢдёҡеүҚжІҝи¶ӢеҠҝжқҘзңӢпјҢеӨ§жЁЎеһӢи®ӯз»ғдҪҝз”Ёзҡ„ж•°жҚ®йӣҶ规模е‘ҲзҺ°зҲҶеҸ‘ејҸеўһй•ҝпјҢеҜ№и®ӯз»ғж•°жҚ®зҡ„ж•°жҚ®йҮҸгҖҒеӨҡж ·жҖ§е’Ңжӣҙж–°йҖҹеәҰж–№йқўд№ҹжҸҗеҮәжӣҙй«ҳзҡ„иҰҒжұӮгҖӮ
гҖҖгҖҖд»ҺеӣҪйҷ…жј”иҝӣиҪЁиҝ№жқҘзңӢпјҢжЁЎеһӢи®ӯз»ғзҡ„ж•°жҚ®и§„жЁЎжӯЈжҖҘеү§иҶЁиғҖгҖӮGPT-1зҡ„ж•°жҚ®йӣҶдёә4.6GBпјҢGPT-3иҫҫеҲ°753GBпјҢиҖҢGPT-4зҡ„ж•°жҚ®йҮҸжҳҜеүҚиҖ…ж•°еҚҒеҖҚгҖӮжҚ®жҺЁжөӢпјҢGPT-5зҡ„и®ӯз»ғж•°жҚ®жңүжңӣзӘҒз ҙ200TBгҖӮ
гҖҖгҖҖе·ҘдёҡеңәжҷҜдёӢпјҢиҝҷдёҖжҢ‘жҲҳжӣҙдёәеӨҚжқӮгҖӮеӣҪйҮ‘иҜҒеҲёз ”жҠҘжҢҮеҮәпјҢе·ҘдёҡйўҶеҹҹж¶өзӣ–е№ҝжіӣпјҢеҢ…жӢ¬41дёӘе·ҘдёҡеӨ§зұ»гҖҒ207дёӘе·Ҙдёҡдёӯзұ»гҖҒ666дёӘе·Ҙдёҡе°Ҹзұ»пјҢеҜјиҮҙж•°жҚ®з»“жһ„еӨҡж ·пјҢж•°жҚ®иҙЁйҮҸеҸӮе·®дёҚйҪҗгҖӮеҗҢж—¶пјҢз”ұдәҺе·Ҙдёҡз”ҹдә§иҝҮзЁӢдёӯзҡ„еҗ„дёӘзҺҜиҠӮзӣёдә’дәӨз»ҮпјҢж•°жҚ®д№Ӣй—ҙзҡ„е…іиҒ”жҖ§е’ҢеӨҚжқӮжҖ§д№ҹиҫғй«ҳгҖӮж•°жҚ®жқҘжәҗгҖҒйҮҮйӣҶж–№ејҸгҖҒж—¶й—ҙжҲізӯүйғҪдјҡеҪұе“Қж•°жҚ®зҡ„еҮҶзЎ®жҖ§е’Ңе®Ңж•ҙжҖ§гҖӮ
гҖҖгҖҖиҝҷз§Қж•°жҚ®з»“жһ„зҡ„еӨҡж ·дёҺиҙЁйҮҸзҡ„еҸӮе·®дёҚйҪҗпјҢз»ҷе·ҘдёҡеӨ§жЁЎеһӢзҡ„и®ӯз»ғе’Ңеә”з”ЁеёҰжқҘжҢ‘жҲҳгҖӮе·Ҙдёҡ AI жһ„е»әпјҢйңҖиҰҒжҠ•е…ҘеӨ§йҮҸзҡ„ж—¶й—ҙе’Ңиө„жәҗиҝӣиЎҢж•°жҚ®жё…жҙ—гҖҒйў„еӨ„зҗҶе’Ңж ЎйӘҢпјҢд»ҘзЎ®дҝқж•°жҚ®зҡ„еҮҶзЎ®жҖ§е’ҢдёҖиҮҙжҖ§гҖӮ
гҖҖгҖҖвҖңеҪ“еүҚеҫҲеӨҡдјҒдёҡеңЁITеұӮйқўе·Із»ҸжІүж·ҖдәҶеӨ§йҮҸж•°жҚ®пјҢдҫӢеҰӮERPгҖҒMESзӯүзі»з»ҹж•°жҚ®пјҢдҪҶеңЁOT(ж“ҚдҪңжҠҖжңҜ)еұӮйқўзҡ„ж•°жҚ®з§ҜзҙҜд»ҚжңүжҳҺжҳҫзҹӯжқҝпјҢе°Өе…¶жҳҜеңЁи®ҫеӨҮеҠ е·ҘгҖҒиҝҗиҫ“гҖҒиЈ…й…Қзӯүеә•еұӮзҺҜиҠӮгҖӮвҖқеңЁ2025дё–з•Ңдәәе·ҘжҷәиғҪеӨ§дјҡдёҠпјҢеҚЎеҘҘж–Ҝзү©иҒ”科жҠҖиӮЎд»Ҫжңүйҷҗе…¬еҸёеүҜжҖ»з»ҸзҗҶи°ўжө·зҗҙеҗ‘ж—¶д»Је‘ЁжҠҘи®°иҖ…иЎЁзӨәпјҢвҖңйҡҸзқҖжҹ”жҖ§еҲ¶йҖ гҖҒиҮӘеҠЁеҢ–еҲ¶йҖ и¶ӢеҠҝзҡ„еҠ йҖҹжҺЁиҝӣпјҢиҝҷйғЁеҲҶOTж•°жҚ®зҡ„йҮҮйӣҶеҸҳеҫ—е°Өдёәе…ій”®гҖӮвҖқ
гҖҖгҖҖи°ўжө·зҗҙиЎЁзӨәпјҢеҚЎеҘҘж–Ҝзҡ„еҒҡжі•жҳҜвҖңд»Һй—®йўҳеҮәеҸ‘еҸҚжҺЁж•°жҚ®вҖқпјҢеҚіе…ҲиҜҶеҲ«е…ій”®дёҡеҠЎй—®йўҳпјҢжҳҺзЎ®жүҖйңҖж•°жҚ®иҰҒзҙ пјҢеҶҚеҺ»иЎҘйҪҗйҮҮйӣҶи·Ҝеҫ„пјҢд»ҺиҖҢзЎ®дҝқж•°жҚ®дёҚд»…йҪҗе…ЁпјҢиҖҢдё”зІҫеҮҶгҖӮ
гҖҖгҖҖвҖңж•°жҚ®жІ»зҗҶжҳҜдёҖдёӘвҖҳд№…д№…дёәеҠҹвҖҷзҡ„зі»з»ҹе·ҘзЁӢпјҢдёҚд»…иҰҒжё…жҙ—гҖҒеҲҶзұ»гҖҒе»әжЁЎпјҢжӣҙйңҖиҰҒеңЁз»„з»ҮжңәеҲ¶дёҠдёәж•°жҚ®иҰҒзҙ жіЁе…Ҙзңҹе®һдёҡеҠЎд»·еҖјгҖӮвҖқи°ўжө·зҗҙејәи°ғпјҢвҖңеҰӮжһңж•°жҚ®иҙЁйҮҸдёҚиҝҮе…іпјҢж— и®әжҳҜйҮҮйӣҶз«ҜиҝҳжҳҜжё…жҙ—з«ҜпјҢи®ӯз»ғеҮәзҡ„жЁЎеһӢд№ҹж— жі•е…·еӨҮе·ҘзЁӢеҸҜз”ЁжҖ§гҖӮвҖқ
гҖҖгҖҖжҺ§еҲ¶жЁЎеһӢвҖңе№»и§үвҖқйЈҺйҷ©
гҖҖгҖҖзӣёжҜ”ж¶Ҳиҙ№дә’иҒ”зҪ‘еҸҜе®№еҝҚдёҖе®ҡзЁӢеәҰзҡ„з”ҹжҲҗиҜҜе·®пјҢе·ҘдёҡеңәжҷҜеҜ№жЁЎеһӢвҖңе№»и§үвҖқзҡ„е®№й”ҷзҺҮеҮ д№Һдёәйӣ¶гҖӮд»»дҪ•дёҖж¬ЎзңӢдјјж— е®ізҡ„еҒҸе·®пјҢеңЁе·ҘдёҡзҺ°еңәйғҪжңүеҸҜиғҪжј”еҢ–дёәе®һиҙЁжҖ§зҡ„е®үе…ЁйЈҺйҷ©жҲ–з»ҸжөҺжҚҹеӨұгҖӮ
гҖҖгҖҖеӣҪжі°еҗӣе®үиҜҒеҲёз ”жҠҘжҢҮеҮәпјҢAI е№»и§ү(AI hallucinations)жҳҜжҢҮдәәе·ҘжҷәиғҪжЁЎеһӢз”ҹжҲҗзҡ„зңӢдјјеҗҲзҗҶдҪҶе®һйҷ…й”ҷиҜҜзҡ„еҶ…е®№пјҢиҝҷз§ҚзҺ°иұЎйҖҡеёёиЎЁзҺ°дёәи„ұзҰ»зҺ°е®һгҖҒйҖ»иҫ‘ж–ӯиЈӮжҲ–еҒҸзҰ»з”ЁжҲ·йңҖжұӮзҡ„иҫ“еҮәгҖӮ
гҖҖгҖҖеӨ§иҜӯиЁҖжЁЎеһӢ(LLM)еңЁз”ҹжҲҗиҝҮзЁӢдёӯеҸҜиғҪж„ҹзҹҘеҲ°дәәзұ»и§ӮеҜҹиҖ…ж— жі•еҜҹи§үжҲ–дёҚеӯҳеңЁзҡ„жЁЎејҸжҲ–зү©дҪ“пјҢд»ҺиҖҢдә§з”ҹжҜ«ж— ж„Ҹд№үжҲ–е®Ңе…ЁдёҚеҮҶзЎ®зҡ„иҫ“еҮәгҖӮиҝҷдәӣй”ҷиҜҜзҡ„жҲҗеӣ еӨҚжқӮеӨҡж ·пјҢеҢ…жӢ¬и®ӯз»ғж•°жҚ®дёҚи¶ігҖҒжЁЎеһӢиҝҮжӢҹеҗҲгҖҒж•°жҚ®еҒҸе·®гҖҒй”ҷиҜҜеҒҮи®ҫд»ҘеҸҠдёҠдёӢж–ҮзҗҶи§ЈдёҚи¶ізӯүгҖӮ
гҖҖгҖҖи°ўжө·зҗҙи®ӨдёәпјҢжҺ§еҲ¶е№»и§үеҝ…йЎ»д»Һдёүж–№йқўе…ҘжүӢпјҡжҸҗеҚҮж•°жҚ®иҙЁйҮҸдёҺиЎҢдёҡзҗҶи§ЈпјҢй«ҳиҙЁйҮҸгҖҒй«ҳеҸҜдҝЎеәҰзҡ„ж•°жҚ®йӣҶжҳҜжЁЎеһӢеҸҜйқ жҖ§зҡ„еҹәзЎҖпјҢиғҢеҗҺеҝ…йЎ»жңүеҜ№иЎҢдёҡе·ҘиүәжөҒзЁӢзҡ„ж·ұеҲ»жҙһеҜҹпјӣ еј•е…ҘеӨ–йғЁзҹҘиҜҶдҪ“зі»пјҢйҖҡиҝҮзҹҘиҜҶеӣҫи°ұгҖҒ专家规еҲҷеә“зӯүеҪўејҸеўһејәжЁЎеһӢиҜӯд№үзҗҶи§ЈдёҺжҺЁзҗҶиғҪеҠӣпјӣ еј•е…ҘжЁЎеһӢж ЎйӘҢжңәеҲ¶пјҢеңЁжЁЎеһӢжҺЁзҗҶд№ӢеҗҺеўһеҠ дәӨеҸүйӘҢиҜҒгҖҒдё“е®¶е®Ўж ЎжҲ–йў„жөӢж ЎйӘҢзӯүжңәеҲ¶пјҢйҳІжӯўжЁЎеһӢвҖңи·‘еҒҸвҖқгҖӮ
гҖҖгҖҖеңЁдә§дёҡе®һи·өдёӯпјҢдјҒдёҡжӯЈе°қиҜ•е°Ҷе№»и§үйЈҺйҷ©еүҚзҪ®жІ»зҗҶгҖӮеңЁ2025дё–з•Ңдәәе·ҘжҷәиғҪеӨ§дјҡдёҠпјҢиҢғејҸйӣҶеӣўй«ҳзә§еүҜжҖ»иЈҒжҹҙдәҰйЈһеҗ‘ж—¶д»Је‘ЁжҠҘи®°иҖ…иЎЁзӨәпјҢе·ҘдёҡеҶізӯ–еңәжҷҜеҜ№еҸҜйқ жҖ§иҰҒжұӮжһҒй«ҳпјҢд»»дҪ•йў„жөӢй”ҷиҜҜйғҪеҸҜиғҪеҜјиҮҙе®һиҙЁжҖ§жҚҹеӨұгҖӮеӣ жӯӨе…¬еҸёеңЁи®ҫи®Ўдёӯеј•е…ҘеҶізӯ–жЁЎеһӢпјҢйҖҡиҝҮе·ҘзЁӢйҖ»иҫ‘гҖҒдёҡеҠЎи§„еҲҷеҜ№жЁЎеһӢиҫ“еҮәиҝӣиЎҢвҖңзәҰжқҹж ЎйӘҢвҖқпјҢжңҖеӨ§йҷҗеәҰең°йҷҚдҪҺе№»и§үйЈҺйҷ©гҖӮ
гҖҖгҖҖеӣҪйҮ‘иҜҒеҲёеҲҷжҸҗеҮәдёҖз§ҚеҸҜиЎҢжһ¶жһ„пјҡвҖңеӨ§жЁЎеһӢжҢҮжҢҘгҖҒе°ҸжЁЎеһӢжү§иЎҢвҖқгҖӮеҚіеңЁйңҖиҰҒе…ЁеұҖдјҳеҢ–е’Ңйў„жөӢжҖ§еҲҶжһҗзҡ„еңәжҷҜдёӯпјҢеҲ©з”ЁеӨ§жЁЎеһӢиҝӣиЎҢе®Ҹи§ӮжҢҮеҜјдёҺеҶізӯ–ж”ҜжҢҒгҖӮиҖҢеңЁе…·дҪ“жү§иЎҢдёҺе®һж—¶еҸҚйҰҲж–№йқўпјҢеҲҷдҫқйқ е°ҸжЁЎеһӢеҸ‘жҢҘе…¶й«ҳзІҫеәҰе’ҢдҪҺжҲҗжң¬зҡ„дјҳеҠҝгҖӮ
гҖҖгҖҖеҢ–и§Је®ҡеҲ¶еҢ–йҖӮй…Қйҡҫйўҳ
гҖҖгҖҖж¶Ҳиҙ№йўҶеҹҹзҡ„еӨ§жЁЎеһӢжӣҙе…іжіЁвҖңе№ҝиҰҶзӣ–вҖқпјҢиҖҢе·ҘдёҡйўҶеҹҹзҡ„еӨ§жЁЎеһӢеҲҷеҝ…йЎ»зӣҙйқўвҖңж·ұз©ҝйҖҸвҖқзҡ„йҡҫйўҳгҖӮ
гҖҖгҖҖе·Ҙдёҡдә’иҒ”зҪ‘зҡ„ж ёеҝғзү№еҫҒжҳҜвҖң1зұіе®ҪпјҢзҷҫзұіж·ұвҖқгҖӮи°ўжө·зҗҙиЎЁзӨәпјҢж— и®әжҳҜжөҒзЁӢе·ҘдёҡиҝҳжҳҜзҰ»ж•Је·ҘдёҡпјҢжҜҸдёҖдёӘз»ҶеҲҶиЎҢдёҡзҡ„е·ҘиүәжөҒзЁӢйғҪй«ҳеәҰдё“дёҡеҢ–гҖҒдёӘжҖ§еҢ–пјҢиЎҢдёҡknow-howжһҒдёәж·ұеҺҡгҖӮиҝҷд№ҹж„Ҹе‘ізқҖе№іеҸ°еһӢдјҒдёҡиӢҘиҰҒзңҹжӯЈе®һзҺ°иғҪеҠӣз©ҝйҖҸпјҢеҝ…йЎ»еҹәдәҺж·ұеҲ»зҡ„иЎҢдёҡзҗҶи§Јеұ•ејҖе®ҡеҲ¶еҢ–йҖӮй…ҚгҖӮ
гҖҖгҖҖеҚЎеҘҘж–ҜиҮӘиә«зҡ„жј”иҝӣи·Ҝеҫ„еҚ°иҜҒдәҶиҝҷдёҖеҲӨж–ӯгҖӮи°ўжө·зҗҙжҢҮеҮәпјҢеҚЎеҘҘж–Ҝиө·жәҗдәҺзҰ»ж•ЈеҲ¶йҖ дёҡпјҢж—©жңҹж·ұеәҰжңҚеҠЎе®¶з”өгҖҒз”өеӯҗгҖҒз”өи„‘зӯүдә§дёҡпјҢ并еңЁжҝҖзғҲеёӮеңәз«һдәүдёӯз§ҜзҙҜдәҶжүҺе®һзҡ„е·ҘдёҡеҹәзЎҖгҖӮиҝҷдәӣз»ҸйӘҢдёҚд»…её®еҠ©еҚЎеҘҘж–Ҝжү“дёӢе·Ҙдёҡж•°еӯ—еҢ–еә•еә§пјҢд№ҹжһ„жҲҗе…¶жӢ“еұ•е…¶д»–зҰ»ж•ЈеҲ¶йҖ й—Ёзұ»зҡ„йҮҚиҰҒж”Ҝж’‘гҖӮ
гҖҖгҖҖеңЁвҖңе·Ҙдёҡе…·иә«жҷәиғҪвҖқйўҶеҹҹпјҢе®ҡеҲ¶еҢ–еҗҢж ·жҳҜз©ҝйҖҸеңәжҷҜзҡ„еүҚжҸҗгҖӮдјҳиүҫжҷәеҗҲиҒ”еҗҲеҲӣе§ӢдәәиөөдёҮз§Ӣеҗ‘ж—¶д»Је‘ЁжҠҘи®°иҖ…иЎЁзӨәпјҢе…·иә«жҷәиғҪзҡ„д»·еҖјдёҚд»…еңЁдәҺиҮӘеҠЁеҢ–ж•ҲзҺҮпјҢжӣҙеңЁдәҺе…¶еҜ№жҹ”жҖ§еҲ¶йҖ и¶ӢеҠҝзҡ„ж”Ҝж’‘иғҪеҠӣгҖӮвҖңд»ҘжүӢжңәеҲ¶йҖ дёәдҫӢпјҢд»ҺиҝҮеҺ»дёҖдёӨдёӘеһӢеҸ·еҲ°зҺ°еңЁжҜҸд»ЈжүӢжңәйғҪеҸҜиғҪжңүжҷ®йҖҡзүҲгҖҒProзүҲгҖҒMaxзүҲзӯүеӨҡз§Қй…ҚзҪ®е’ҢйўңиүІпјҢж¶Ҳиҙ№иҖ…дёӘжҖ§еҢ–йңҖжұӮзҡ„жҸҗеҚҮжӯЈеңЁеҖ’йҖјз”ҹдә§жөҒзЁӢжҹ”жҖ§еҢ–гҖӮвҖқ
гҖҖгҖҖиөөдёҮз§ӢжҢҮеҮәпјҢдјҳиүҫжҷәеҗҲжһ„е»әзҡ„йқўеҗ‘е·Ҙдёҡе®һйҷ…йңҖжұӮзҡ„е…·иә«жҷәиғҪзі»з»ҹпјҢжӯЈжҳҜж”Ҝж’‘иҝҷз§ҚеҸҳеҢ–зҡ„еҹәзЎҖи®ҫж–ҪгҖӮеҖҹеҠ©е…·иә«жҷәиғҪжңәеҷЁдәәеҸҠе…¶и°ғеәҰзі»з»ҹпјҢе·ҘеҺӮиғҪеӨҹе®һзҺ°зү©ж–ҷеңЁдёҚеҗҢз”ҹдә§иҠӮзӮ№й—ҙзҡ„жҷәиғҪжөҒиҪ¬дёҺеҠЁжҖҒи°ғж•ҙпјҢж»Ўи¶іеӨҡе“Ғзұ»гҖҒе°Ҹжү№йҮҸгҖҒй«ҳйў‘ж¬Ўзҡ„е®ҡеҲ¶еҢ–з”ҹдә§йңҖжұӮгҖӮ
гҖҖгҖҖз®—жі•еұӮйқўзҡ„йҖӮй…ҚжҢ‘жҲҳеҗҢж ·дёҚе®№еҝҪи§ҶгҖӮжҹҙдәҰйЈһиЎЁзӨәпјҢе…¬еҸёеңЁе®һйҷ…еә”з”Ёдёӯйқўдёҙзҡ„жңҖеӨ§жҢ‘жҲҳд№ӢдёҖпјҢжҳҜжҜҸзұ»еңәжҷҜзҡ„ж•°жҚ®з»“жһ„е’Ңзү№еҫҒеҫҖеҫҖе·®ејӮе·ЁеӨ§гҖӮжӯӨеӨ–пјҢеңЁе·ҘзЁӢе®һи·өдёӯд№ҹдјҡеҜ№жЁЎеһӢиҝӣиЎҢвҖңе°ҒиЈ…вҖқејҸзҡ„йҖӮй…ҚпјҢдёҚеҗҢеә”з”ЁеңәжҷҜжүҖжҺҘе…Ҙзҡ„еӨ§жЁЎеһӢиҷҪ然еә•еұӮдёҖиҮҙпјҢдҪҶи°ғз”Ёж–№ејҸгҖҒиҫ“е…Ҙиҫ“еҮәжҺҘеҸЈйғҪеҸҜд»ҘеҒҡеҮәе·®ејӮеҢ–и®ҫи®ЎгҖӮ
гҖҖгҖҖдёҺйҖҡз”ЁеӨ§жЁЎеһӢдё»иҰҒеӨ„зҗҶж–Үжң¬иҫ“е…Ҙиҫ“еҮәдёҚеҗҢпјҢ第еӣӣиҢғејҸ(06682.HK)зҡ„еһӮзӣҙжЁЎеһӢжӣҙеҒҸеҗ‘д»»еҠЎеҜјеҗ‘еһӢгҖӮдҫӢеҰӮпјҢеңЁвҖңеҠһдәӢеһӢвҖқеңәжҷҜдёӯпјҢеӨ§жЁЎеһӢзҡ„ж ёеҝғдҪңз”ЁдёҚжҳҜз”ҹжҲҗж–Үжң¬пјҢиҖҢжҳҜйў„жөӢвҖңдёӢдёҖдёӘеҠЁдҪңвҖқжҲ–вҖңдёӢдёҖдёӘзҠ¶жҖҒвҖқгҖӮд»ҘеңЁеҲ¶йҖ зҺҜиҠӮдёӯзҡ„дә§йҮҸйңҖжұӮйў„жөӢдёәдҫӢпјҢжЁЎеһӢзҡ„д»»еҠЎе°ұжҳҜж №жҚ®еҪ“еүҚзҡ„еӨҡз»ҙж•°жҚ®иҫ“е…ҘпјҢйў„жөӢжҳҺеӨ©зҡ„з”ҹдә§йңҖжұӮгҖӮиҝҷз§Қйў„жөӢзұ»еә”з”Ёжң¬иҙЁдёҠжӣҙиҙҙиҝ‘вҖңе№ҝд№үжҷәиғҪеҶізӯ–вҖқпјҢиҖҢйқһзәҜзІ№зҡ„иҜӯиЁҖз”ҹжҲҗгҖӮ
гҖҖгҖҖ(иҙЈд»»зј–иҫ‘пјҡи‘ЈиҗҚиҗҚ ) гҖҖгҖҖгҖҖгҖҖгҖҗе…ҚиҙЈеЈ°жҳҺгҖ‘жң¬ж–Үд»…д»ЈиЎЁдҪңиҖ…жң¬дәәи§ӮзӮ№пјҢдёҺе’Ңи®ҜзҪ‘ж— е…ігҖӮе’Ңи®ҜзҪ‘з«ҷеҜ№ж–ҮдёӯйҷҲиҝ°гҖҒи§ӮзӮ№еҲӨж–ӯдҝқжҢҒдёӯз«ӢпјҢдёҚеҜ№жүҖеҢ…еҗ«еҶ…е®№зҡ„еҮҶзЎ®жҖ§гҖҒеҸҜйқ жҖ§жҲ–е®Ңж•ҙжҖ§жҸҗдҫӣд»»дҪ•жҳҺзӨәжҲ–жҡ—зӨәзҡ„дҝқиҜҒгҖӮиҜ·иҜ»иҖ…д»…дҪңеҸӮиҖғпјҢ并иҜ·иҮӘиЎҢжүҝжӢ…е…ЁйғЁиҙЈд»»гҖӮйӮ®з®ұпјҡnews_center@staff.hexun.com гҖҖгҖҖ